Nov 21, 2025
From Sensing to Creation:
How Sony’s Research at ICCV 2025
Connected the Physical and the Imaginative Worlds of AI

At ICCV 2025, one of the world’s leading conferences on computer vision, Sony presented eight papers that traced the full spectrum of visual AI—from sensing and perception to processing and generation. The research spanned innovations in depth estimation, RAW-domain object detection, and intrinsic image quality, as well as advances in efficient vision transformers and guided diffusion models. This body of work explored how machines can not only see the world, but interpret and create within it.
Seeing the World More Accurately
Before machines could interpret, they first had to perceive. At ICCV 2025, Sony researchers returned to the fundamentals of vision: how light becomes information, and information becomes understanding.
Several papers focused on making that perception not only sharper but truer to reality—capturing depth more completely, processing color more adaptively, and judging quality more intelligently.
In "ToF-Splatting: Dense SLAM using Sparse Time-of-Flight Depth and Multi-Frame Integration," researchers tackled one of computer vision’s oldest challenges: reconstructing 3D spaces from incomplete depth and color data. By integrating very sparse depth data across multiple frames, ToF-Splatting produces dense 3D reconstructions in the form of a simplified Gaussian Splat that leverages additional depth cues optimally and flexibly over time. As the authors noted, “our method enables dense SLAM using very sparse, low frame rate ToF depth and Gaussian Splatting as the 3D representation, effectively enabling optimal use of sparse depth sensors in dense reconstruction.
That approach mirrors how the human visual system infers structure from sparse or noisy cues using context and motion to fill in what the eyes cannot directly measure. In ToF-Splatting, even when a sensor captures as few as 64 depth points per frame, the system integrates those sparse signals across multiple views to reconstruct a coherent 3D scene more accurately than baselines using only, e.g., monocular depth. This ability to recover spatial structure from incomplete data marks a crucial step toward more reliable perception for autonomous systems and augmented reality.
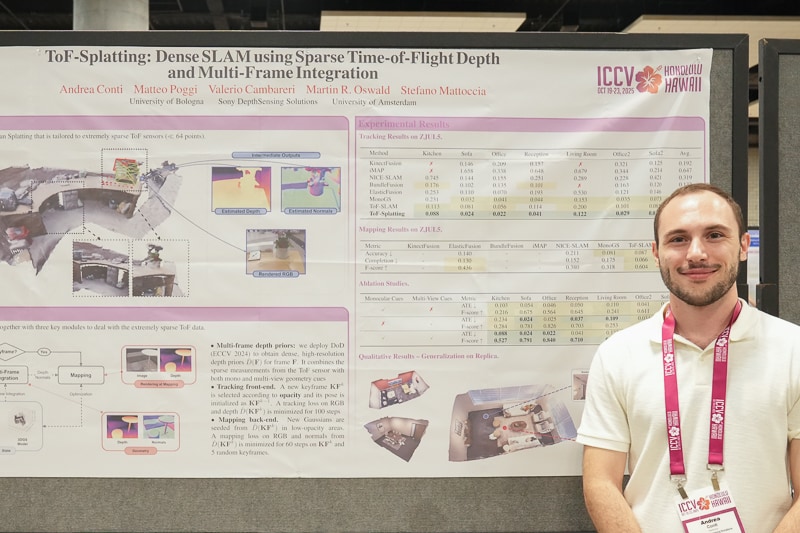
Andrea Conti, Sony Depthsensing Solutions, posing alongside the ToF-Splatting poster at ICCV 2025
The idea of perceiving beyond the visible continued in "Beyond RGB: Adaptive Parallel Processing for RAW Object Detection." Traditional detectors rely on sRGB images that have already passed through image signal processing pipelines. By working directly with RAW data, Sony’s team bypassed those limitations. As the authors described, “RAW data retains information that is lost after standard ISP operations such as demosaicing and tone mapping.” Their adaptive RAW Adaptation Module (RAM) processed attributes like color and luminance in parallel, producing detections that better reflected how sensors (and in some respects, the human eye) perceive a scene.
This philosophy of perception extended further in "Image Intrinsic Scale Assessment (IISA)." The paper questioned the assumption that higher resolution automatically means higher quality. In their words, “resolution does not necessarily correlate with perceived quality.” The authors defined the Image Intrinsic Scale (IIS) as “the largest downscaling ratio where an image reaches its highest perceived quality,” offering a perceptual metric that aligns evaluation with human visual experience.
Viewed together, these three works formed a coherent exploration of realism, from ToF-Splatting’s recovery of hidden depth, to Beyond RGB’s embrace of unfiltered light, to IISA’s redefinition of quality. Sony’s sensing research did not just aim to capture the world; it strove to understand how the world is captured.
Processing Information More Efficiently
Once information is captured, the next challenge is processing it efficiently and intelligently. The next cluster of papers focused on making computer-vision systems lighter, faster, ensuring that the intelligence built into devices did not come at the cost of computation or memory.
In "Learning Hierarchical Line Buffer for Image Processing," researchers rethought one of the most fundamental components of imaging pipelines: the line buffer. Typically treated as a static structure, the buffer determines how pixel data moves through an image processor. By learning a hierarchical version of it, the team introduced adaptability at the hardware–software interface itself. As they explained, "the hierarchical buffer model learns inter-line dependencies efficiently, achieving a superior trade-off between performance and memory efficiency."
It was a quiet but crucial innovation: optimizing the invisible scaffolding that underlies nearly every visual application, from smartphone photography to edge-based detection. Efficiency, in this case, became a form of intelligence.
That same efficiency ethos continued in "MixA: A Mixed Attention Approach with Stable Lightweight Linear Attention to Enhance Efficiency of Vision Transformers at the Edge." Vision Transformers (ViTs) deliver state-of-the-art accuracy but demand heavy compute. MixA offers a hybrid attention design combining quadratic attention in critical layers with a new lightweight module called SteLLA (Stable Lightweight Linear Attention). As the authors described, "MixA strategically applies different attention mechanisms, using ReLU-based quadratic attention for critical layers while employing ReLU-based linear attention for others, resulting in a balanced trade-off between efficiency and performance."
The result: ViTs that achieved up to 22 % faster inference on Apple’s M1 chip with only 0.1 % accuracy drop, making them viable for on-device deployment.
Efficiency also drove "DuET: Dual Incremental Object Detection via Exemplar-Free Task Arithmetic." The work addressed ‘catastrophic forgetting’, which is how models lose performance on older tasks when trained on new ones. Instead of storing exemplar images, DuET applied a dual-branch optimization scheme that separated old and new knowledge through “task arithmetic.”
"Our method eliminates the need for exemplar storage, achieving dual incremental learning while maintaining accuracy across evolving object detection tasks," the authors note.
Together, these papers reimagined how intelligence could live closer to the sensor, lighter on the processor, and more flexible in memory, bringing advanced vision within reach of edge and embedded devices.
Creating with AI
If perception and efficiency represented the body and mind of visual AI, creativity was its imagination. The final group of papers explored how models could adapt, generate, and align with human guidance—advancing generative systems that were both expressive and controllable.
In “Transformed Low-rank Adaptation via Tensor Decomposition and Its Applications to Text-to-Image Models,” or TLoRA, researchers extended low-rank adaptation through tensor mathematics. Rather than updating a dense network of parameters directly, they introduced a full-rank transform and a low-rank residual adaptation parameterized via tensor decomposition. As they wrote, “our approach decomposes adaptation into structured low-rank tensors, achieving stable fine-tuning while maintaining generative quality.”
This enabled models like Stable Diffusion XL to adapt efficiently to new styles or subjects with as few as 0.4 million parameters, preserving image fidelity while cutting training cost dramatically.
In "TITAN-Guide: Taming Inference-Time Alignment for Guided Text-to-Video Diffusion Models," researchers tackled the challenge of steering video diffusion models without retraining and overloading memory. The method replaced memory-intensive backpropagation with forward gradients that optimized guidance signals directly during inference. As the authors noted, “TITAN-Guide eliminates the need for backpropagation by leveraging forward gradients, enabling efficient memory usage while maintaining alignment between video and guidance signals.”
The model achieved strong alignment on benchmarks while reducing memory consumption by roughly 45 %, supporting multimodal conditioning such as style, audio, and text.
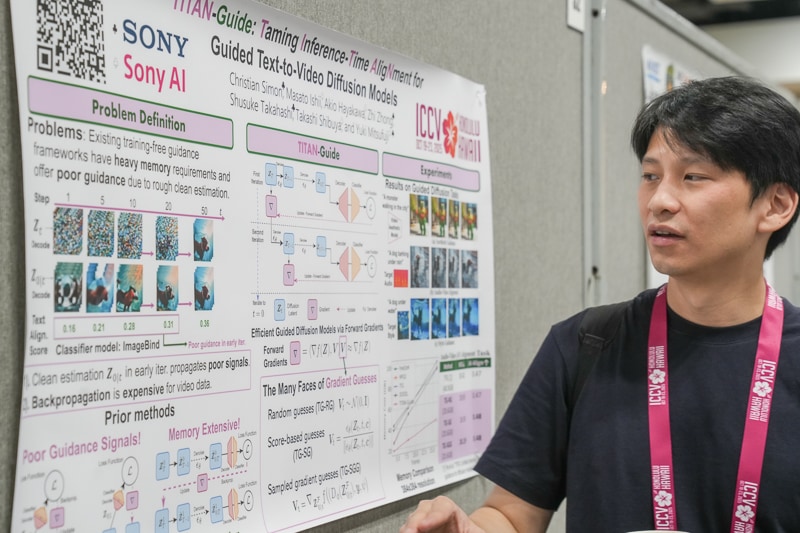
Christian Simon, Sony Group Corporation, introduces the TITAN-Guide poster at ICCV 2025
Together, these works represented generative systems that were not only efficient but also collaborative, and able to "take direction" and create in dialogue with human intent.
Outstanding Reviewer Recognition
Sony AI researcher Jiacheng Li was selected as an Outstanding Reviewer for ICCV 2025; an honor awarded to fewer than 3 % of all reviewers (321 out of 11,859). This recognition reflects the rigor and integrity that Sony researchers bring not only to their own work but to the peer review process itself.
Workshops, Tutorials & Invited Talks
In addition to its eight accepted main conference papers, Sony contributed to a diverse set of workshops, tutorials, and invited sessions at ICCV 2025, reflecting the breadth of its research across imaging, sensing, generative AI, and human understanding. These sessions highlighted Sony’s commitment to open collaboration and cross-disciplinary exchange within the global computer vision community.

Masato Ishii, Sony AI, presents the Generative AI for Audio-Visual Content Creation workshop at ICCV 2025
Workshops Hosted and Co-organized by Sony
2nd AI for Content Generation; Quality Enhancement and Streaming
Workshop site • ICCV virtual page
Organized by Marcos V. Conde, Radu Timofte, Eduard Zamfir, Julian Tanke (Sony AI), Takashi Shibuya (Sony AI), Yuki Mitsufuji (Sony Group Corporation/Sony AI), Varun Jain, Fan Zhang, Heather Yu.
Now in its second edition, this workshop united advances in deep learning for streaming, compression, and visual quality enhancement. Discussions centered on neural codecs, generative compression, and content rendering for the next era of streaming media.
Generative AI for Audio-Visual Content Creation
Workshop site • ICCV virtual page
Organized by Masato Ishii (Sony AI), Takashi Shibuya (Sony AI), Yuki Mitsufuji (Sony Group Corporation/Sony AI), Ho Kei Cheng, Alexander Schwing, Prem Seetharaman, Oriol Nieto, Justin Salamon, David Bourgin, Bryan Russell, Ziyang Chen, Sanjoy Chowdhury.
This workshop explored generative models for joint audio-visual synthesis, bridging modalities to create more immersive and interactive media experiences. Topics included cross-modal generation, vision-to-audio translation, and multimodal alignment.
AIM 2025 Real-World RAW Denoising Challenge
Challenge site • Codabench competition
Hosted within the Advances in Image Manipulation (AIM) workshop, this Sony-led challenge focused on camera-agnostic RAW image denoising using self-supervised techniques. Organizers included Feiran Li (Sony AI), Jiacheng Li (Sony AI), Marcos V. Conde, Beril Besbinar (Sony AI), Vlad Hosu (Sony AI), Daisuke Iso (Sony AI), Radu Timofte.
The benchmark introduced multi-camera datasets and evaluation protocols for developing denoising methods that generalize across devices and environments.
Invited Talks and Tutorials
Invited Talk: AI for Creators: Pushing Creative Abilities to the Next Level
Presented by Yuki Mitsufuji (Sony Group Corporation/Sony AI) at the 2nd AI for Content Generation; Quality Enhancement and Streaming workshop.
This talk reflected Sony AI’s ongoing initiative to expand human creativity through AI tools for audio, video, and multimodal storytelling.
Tutorial: A Tour Through AI-powered Photography and Imaging
Tutorial site • ICCV virtual page
Presented by Jiacheng Li (Sony AI), this tutorial provided a guided overview of modern imaging pipelines enhanced by neural networks, covering learned ISPs, restoration, and data-driven image enhancement.

Jiacheng Li, Sony AI, presents in a tutorial, A Tour Through AI-powered Photography and Imaging at ICCV 2025
Workshop Papers Featuring Sony Contributions
Sony researchers and teams also co-authored papers presented in a range of specialized workshops spanning skilled activity understanding, event-based vision, neuromorphic sensing, multimodal data, and affective computing:
• EgoOops: A Dataset for Mistake Action Detection from Egocentric Videos referring to Procedural Texts — First Workshop on Skilled Activity Understanding; Assessment and Feedback Generation, authored by Yuto Haneji, Taichi Nishimura (Sony Interactive Entertainment), Hirotaka Kameko, Keisuke Shirai, Tomoya Yoshida, Keiya Kajimura, Koki Yamamoto, Taiyu Cui, Tomohiro Nishimoto, Shinsuke Mori
• Lattice-allocated Real-time Line Segment Feature Detection and Tracking Using Only an Event-based Camera — 2nd Workshop on Neuromorphic Vision (NeVi): Advantages and Applications of Event Cameras, authored by Mikihiro Ikura, Arren Glover, Masayoshi Mizuno (Sony Interactive Entertainment), Chiara Bartolozzi
• GraphEnet: Event-driven Human Pose Estimation with a Graph Neural Network — 2nd Workshop on Neuromorphic Vision (NeVi): Advantages and Applications of Event Cameras, authored by Gaurvi Goyal, Pham Cong Thuong, Arren Glover, Masayoshi Mizuno (Sony Interactive Entertainment), Chiara Bartolozzi
• Extreme Compression of Adaptive Neural Images — The 3rd workshop on Binary and Extreme Quantization for Computer Vision, authored by Leo Hoshikawa (Sony Interactive Entertainment), Marcos V. Conde, Takeshi Ohashi (Sony Group Corporation), Atsushi Irie (Sony Group Corporation)
• Towards reporting bias in visual-language datasets: bimodal augmentation by decoupling object-attribute association — The Second Workshop on Multimodal Representation and Retrieval, authored by Qiyu Wu (Sony Group Corporation/The University of Tokyo), Mengjie Zhao (Sony Group Corporation), Yutong He, Lang Huang, Junya Ono (Sony Group Corporation), Hiromi Wakaki (Sony Group Corporation), Yuki Mitsufuji (Sony Group Corporation/Sony AI)
• SpecMaskFoley: Efficient Yet Effective Synchronized Video-to-audio Synthesis via Pretraining and ControlNet — Generative AI for Audio-Visual Content Creation , authored by Zhi Zhong (Sony Group Corporation), Akira Takahashi (Sony Group Corporation), Shuyang Cui (Sony Group Corporation), Keisuke Toyama (Sony Group Corporation), Shusuke Takahashi (Sony Group Corporation), Yuki Mitsufuji (Sony Group Corporation/Sony AI)
• AIM 2025 Challenge on Real-World RAW Image Denoising — Advances in Image Manipulation Workshop and Challenges, authored by Feiran Li (Sony AI), Jiacheng Li (Sony AI), Marcos V. Conde, Beril Besbinar (Sony AI), Vlad Hosu (Sony AI), Daisuke Iso (Sony AI), Radu Timofte
• Multimodal Viewer Responses to Japanese Manzai Comedy Dataset for Affective Computing — 9th Workshop and Competition on Affective & Behavior Analysis in-the-wild (ABAW), authored by Kazuki Kawamura (Sony CSL-Kyoto/Sony Group Corporation/The University of Tokyo), Kengo Nakai, Jun Rekimoto (Sony CSL-Kyoto/The University of Tokyo)
• Sparse Multiview Open-Vocabulary 3D Detection — 5th Workshop on Open-World 3D Scene Understanding, authored by Olivier Moliner (Centre for Mathematical Sciences, Lund University/Sony Corporation, Lund Laboratory, Sweden), Viktor Larsson, Kalle Astrom
• DMS: Diffusion-Based Multi-Baseline Stereo Generation for Improving Self-Supervised Depth Estimation — Advances in Image Manipulation Workshop and Challenges, authored by Zihua Liu, Yizhou Li (Sony Semiconductor Solutions Group), Songyan Zhang, Masatoshi Okutomi
These workshops and tutorials underscored Sony’s multifaceted role at ICCV 2025, not only presenting research papers but also hosting collaborative platforms for the exchange of ideas on imaging, sensing, and generative creativity. Together, they reflected an aspect of Sony’s enduring vision: connecting the physics of perception with the art of creation.

Chiara Bartolozzi, Istituto Italiano di Tecnologia, and Masayoshi Mizuno, Sony Interactive Entertainment, posing alongside the GraphEnet poster at ICCV 2025
The Full Spectrum
Viewed together, Sony’s ICCV 2025 papers don’t suggest a deliberate grand narrative, but instead, have a natural continuity—each building on different facets of computer vision.
At one end of that spectrum lays the world as it is: light scattering off surfaces, captured as depth, color, and signal. On the other end, lay the world as it could be: synthetic images and videos generated through guided diffusion. Between them was the quiet, essential work of optimization: attention modules that balance performance and power, buffers that learn to process more intelligently, and models that evolve without forgetting.
This continuum reflects something characteristic of Sony’s research: progress that emerges not from a single objective but from the steady refinement of how machines see, adapt, and create.
At ICCV 2025, the message running through all of Sony’s work is not simply about scale or performance—it is about connection.
Between sensors and models.
Between efficiency and imagination.
Between the physical light that hits a lens and the creative light that sparks an idea.
That full-stack vision defines Sony’s research trajectory. As these eight papers demonstrate, innovation doesn’t live in one domain of AI—it emerges when every layer, from photons to pixels to prompts, evolves together.






